ETH-交易树和收据树
每次发布一个区块的时候,这个区块所包含的交易,会组织成一棵交易树,也是一棵Merkle tree,和比特币的情况是类似的,同时,以太坊还增加了一个收据树,每个交易执行完之后,会形成一个交易,记录这个交易的相关信息,也就是说,收据树和交易树上面的结点是一一对应的。
增加这个收据树主要是考虑到以太坊的智能合约执行过程比较复杂,增加收据树的结构有利于我们快速查询一些执行的结果,从数据结构上来看,收据树和交易树都是MPT(Merkle Patricia tree),和比特币有所区别,比特币中的交易树,就是用普通的Merkle tree。为什么有这个区别?可能是为了方便,以太坊中的三棵树都用同样的结构,代码比较统一,不一定有什么深层次的原因,当然,用MPT的一个好处是:它支持查找操作,它支持通过键值,从顶向下,沿着树进行查找,对于状态树来说,查找的键值,就是这个账户的地址;对于交易树和收据树来说,查找的键值就是这个交易在发布的区块里面的序号(交易的发布顺序是由发布区块的那个结点决定的)。
交易树和收据树都是只把当前发布的区块里的交易组织起来的,而状态树,是把系统中所有账户的状态都要包含进去,不管这些账户和当前交易有没有关系。
多个区块的状态树是共享结点的,每次新发布一个区块的时候,只有这个区块里的交易影响了账户状态那些结点需要新建一个分支,其他的结点都是沿用原来状态树上的结点就行了。相比之下,每个区块的交易树和收据树都是独立的,他们是不会共享节点的,每个区块中发布的交易本身我们也认为是独立的。
交易树和收据树的用途?
①提供Merkle Proof,就像比特币当中,交易树可以向轻结点证明某个交易被打包到某个区块里了;收据树也是类似的,你要证明某个交易的执行结果也是在收据树中提供一个Merkle Proof。
②除此之外,以太坊还支持一些更加复杂的查询操作,比如说,你想找到过去十天当中,所有跟智能合约有关的交易:一种办法是,把过去十天产生交易的区块都扫描一遍,看看其中有哪些交易和智能合约相关(复杂度比较高,而且对于轻结点来说,没有交易列表,它只有一个块头信息,所有轻结点也没有办法通过扫描所有交易列表的方法,找到符合条件的交易);以太坊中引入了bloom filter。
bloom filter
bloom filter:这个数据结构可以支持比较高效的查找某个元素是不是在一个比较大的集合里面,比如有个很大的集合,你先知道某个指定的元素是不是在这个集合里,怎么办?
一种比较笨的方法,遍历集合,但是这个复杂度是线性的(这个的前提是你得有足够的存储来保存整个集合的元素),对于轻结点来说,他没有交易列表(没有整个集合的元素信息);
bloom filter使用了一种比较巧妙的思想,给这个大的集合,计算出一个很紧凑的摘要
比如有一个128位的向量,集合中的每一个函数通过哈希函数取哈希,找到向量中的对应位置,然后把他置成1(向量每个位置的初始值为0),所有的元素都处理完了,得到的这个向量,就是原来集合的摘要,这个摘要比原来的集合要小很多,比如我们这个例子中,用一个128位的向量就可以代表一个集合了。
这个摘要有什么用?
我们现在有一个元素d,想知道d是不是在集合中,但是这个集合本身我们不一定能够保存下来,应该怎么办?
我们用给定的哈希函数,给d取哈希值,看他映射的位置,如果该位置向量的值为0,说明这个元素一定不在这个集合里,假设是1,①确实是集合中的元素;②也有可能不在集合中,恰好出现了哈希碰撞而已
所以,使用bloom filter,有可能会出现false positive,但是不会出现false negative(在里面他一定在里面,不在里面他有可能在里面)。
有的bloom filter的设计,不是用的一种哈希函数,而是用的一组哈希函数,那么每个哈希函数,独立地把这个函数映射到向量中的某一个位置,用一组哈希函数的好处是,不会所有的哈希函数都出现碰撞。
如果从集合中删除一个元素,该怎么操作?
bloom filter的一个局限性是,不支持删除操作,把映射为1的位置改成0,可能其他的元素也映射到这里(哈希碰撞是可能的),所以简单的bloom filter是不支持删除操作的,如果要支持删除操作,就不能是0/1表示有还是没有了,得改成计数器得形式,还要考虑这个计数器会不会overflow,这样这个数据结构就很复杂了,与初衷是相违背的。
以太坊中bloom filter的作用?
每个交易执行完之后会形成一个收据,这个收据里面就会有一个bloom filter,记录这个交易的类型,地址等其他信息,发布的区块的块头里,也有一个总的bloom filter,这个总的bloom filter是这个区块里所有交易的bloom filter的一个并集
所以你要根据条件查找交易(我要最近十天之内和智能合约相关的交易)?
先查一下哪个区块的块头里的bloom filter有我要的这个交易的类型,如果块头里的bloom filter没有的话,那么这个区块就不是我们想要的,如果有的话,我们再去查找这个区块里包含的交易所对应的收据树里的那些bloom filter,有可能都没有(false positive),如果是有的话,找到相对应的交易确认。
这个好处是什么?
好处是能够快速过滤掉大量无关的区块,剩下的一些少数的“候选区块”我们再仔细查看,比如你是轻结点,你只有块头信息,那么根据块头,就已经可以过滤掉很多区块了,剩下有可能是你想要的区块,可以问全节点要一些进一步的信息。
以太坊的三棵树的哈希值都包含在块头里面的,以太坊的运行过程可以把它看成transaction-driven state machine(交易驱动状态机),这个状态机的状态是:所有账户的状态,就是状态树中包含的内容,那么交易是:每个发布的区块中包含的交易,通过执行这些交易,驱动当前系统从当前状态转移到下一个状态。
比特币你也可以认为是一个交易驱动的状态机,那么比特币中的状态是:UTXO(没有被花掉的交易的输出),每次新发布一个区块,会从UTXO用掉一些输出,又会增加一些输出,所以发布的这个区块会驱动这个状态机从当前状态转移到下一个状态。
比特币和以太坊中的状态机有一个共同特点,就是状态转移得是确定性的:对一个给定的当前状态,一组给定的交易,能够确定性的转移到下一个状态,因为所有的全节点,所有的矿工,都要执行相同的状态转移,所以状态转移必须是确定性的。
有人在以太坊上发布了一个交易,某个结点收到这个交易(A转账给B),有没有可能这个收款人的地址,以前从来没有听说过?
可能的,创建账户的时候不需要通知其他人的,只有这个账户第一次收到钱的时候,其他账户才会知道这个账户的存在,这个时候要在状态树中新插入一个结点
我们前面所讲的交易树,收据树,状态树的一个区别是状态树要包含所有账户的状态,能不能把这个状态树的设计改一下,改成状态树也只包含这个区块相关的那些账户的状态,这样就和交易树和收据树一致了,而且还大幅度的削减每个区块所对应的状态树的大小?
你要想查找某个账户的状态就不方便了,还有另外一个问题在于:A要赚钱给B,你要知道A的状态才能转钱给B,也要知道B的状态是什么,当前余额是多少,因为你要收钱,所以A、B的状态都要找到,而B这个账户有可能是新创建的账户,这个时候你要找到创世纪块去,才发现B这个账户不存在。
代码
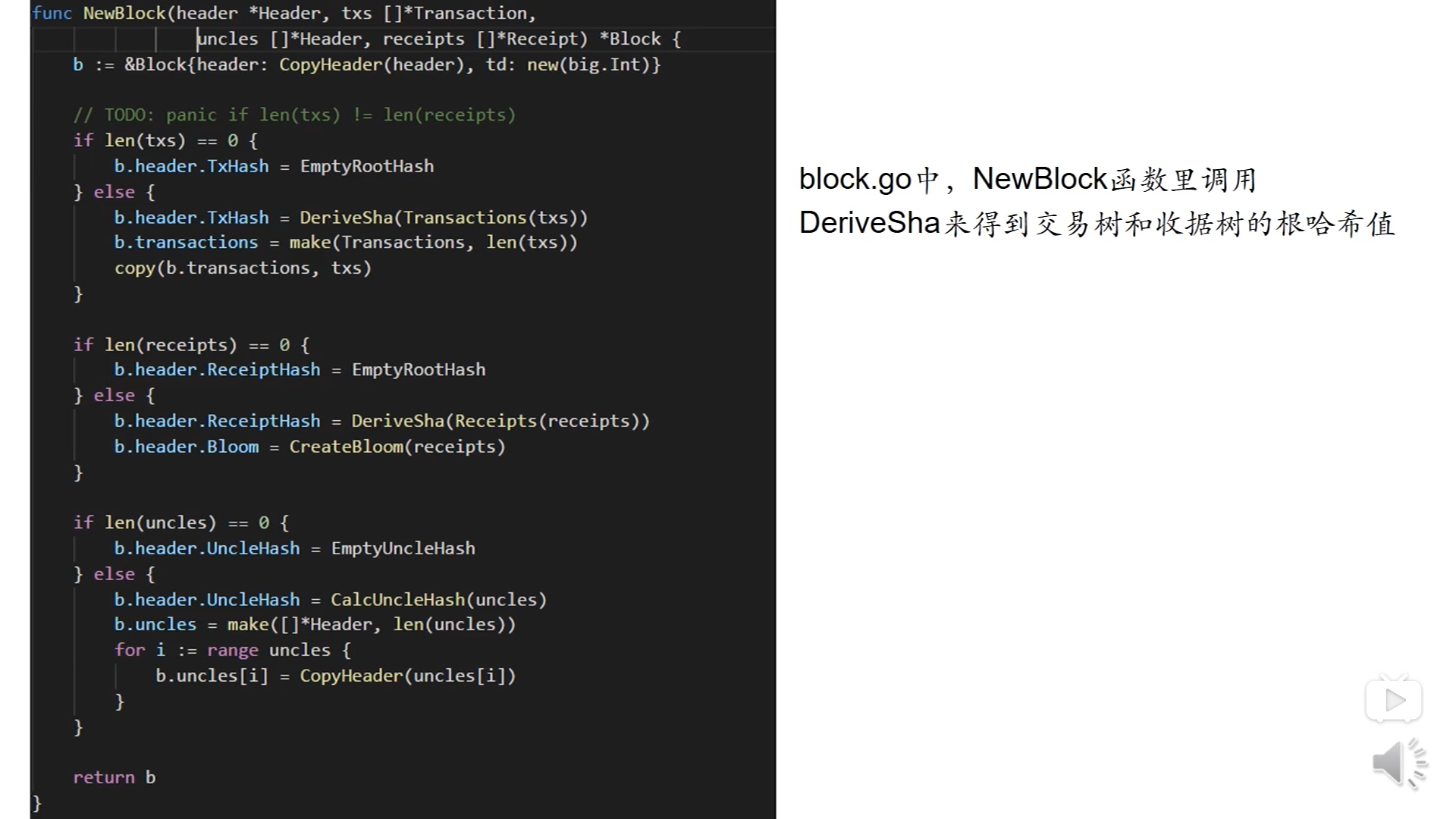
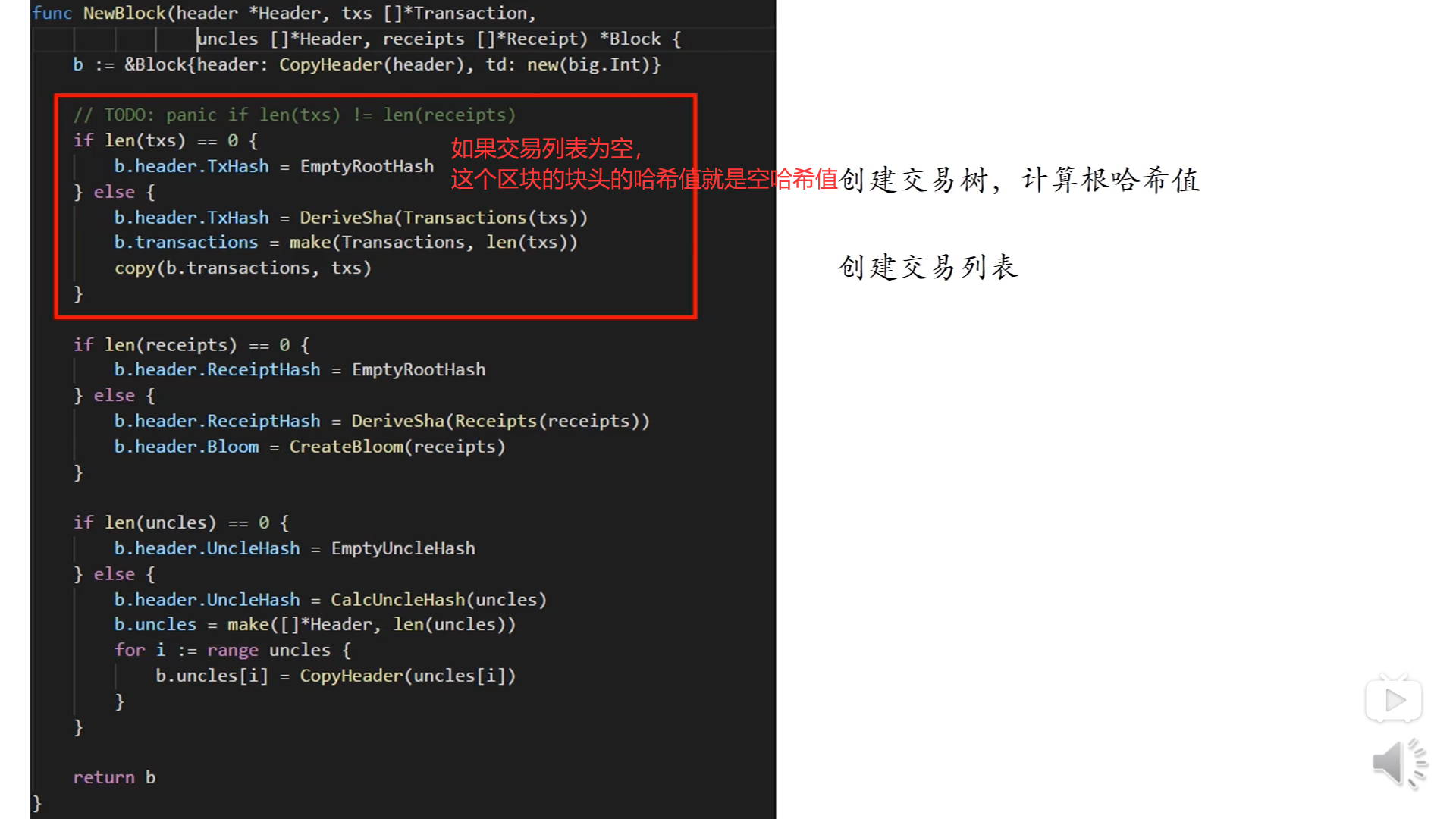
上图第一个判断是交易树的代码,如果交易列表是空的话,那么交易树的根哈希值就是一个空哈希值,否则的话,通过调用DeriveSha来得到交易树的根哈希值,然后创建这个区块的交易列表;
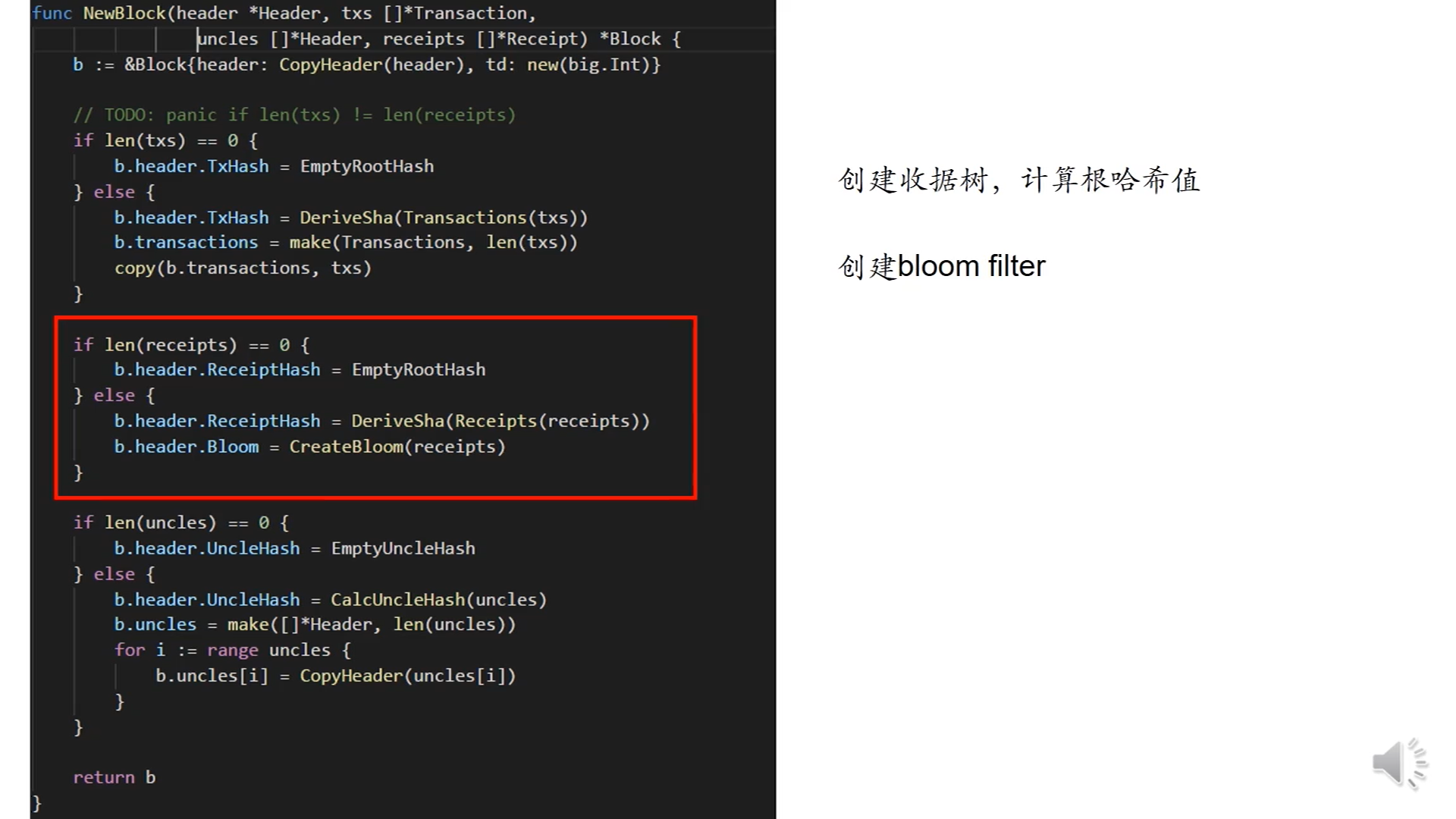
中间的代码是收据树,同样判断收据列表是否为空,如果是空的话,收据列表块头的哈希值就是一个空哈希值,否则的话,和交易树相同,交易列表的长度和收据列表的长度是相同的
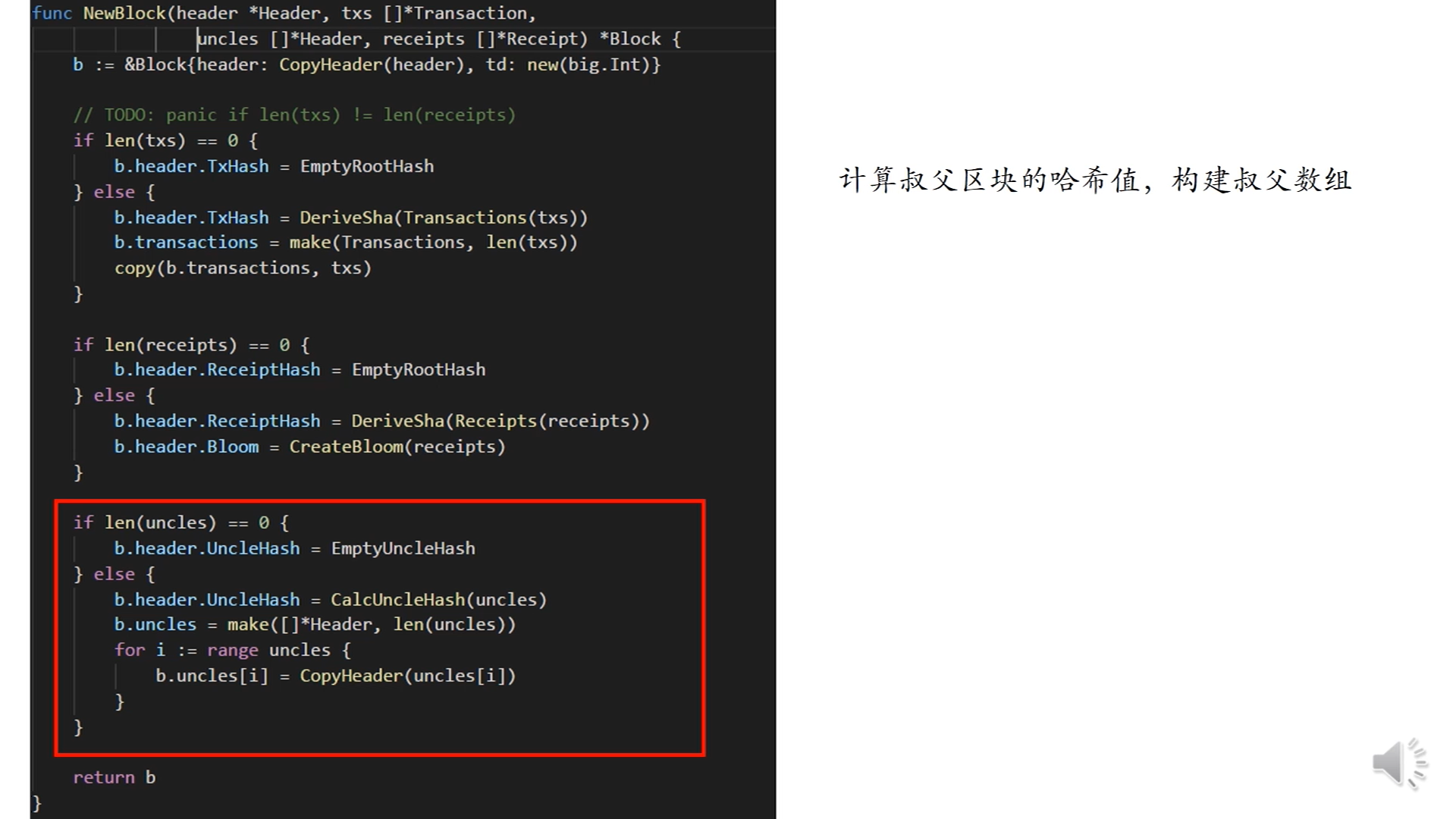
下面的代码是处理叔父区块的,首先判断叔父列表是否为空,如果是的话,舒服区块的根哈希值就是个空哈希值,否则,通过调用CalcUncleHash计算哈希值,然后通过一个循环构建区块里的叔父数组(叔父列表和交易树和收据树没有关系)
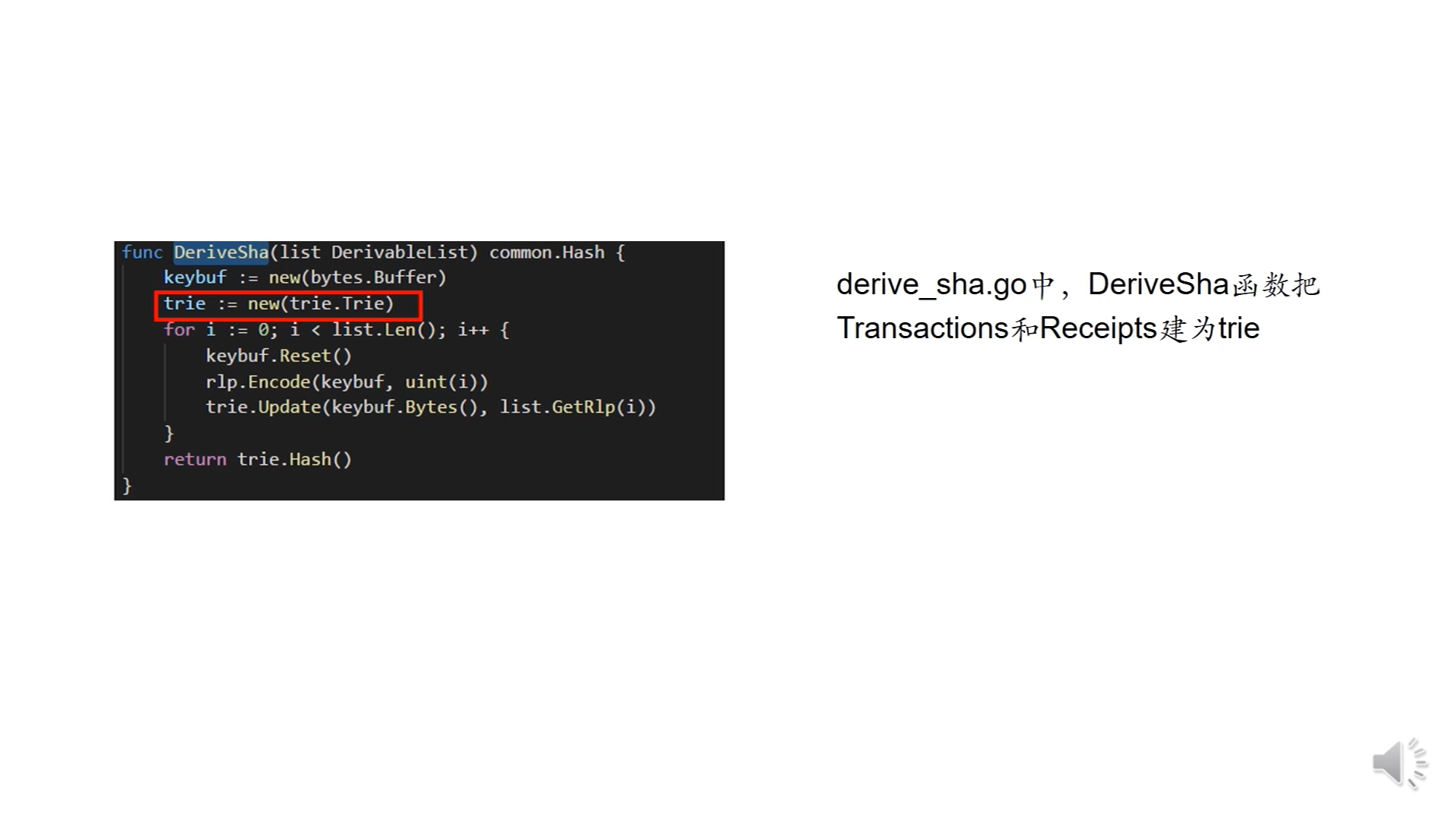
创建交易树和收据树使用的都是这个函数,这里创建的数据结构(收据树和交易树)是一个trie
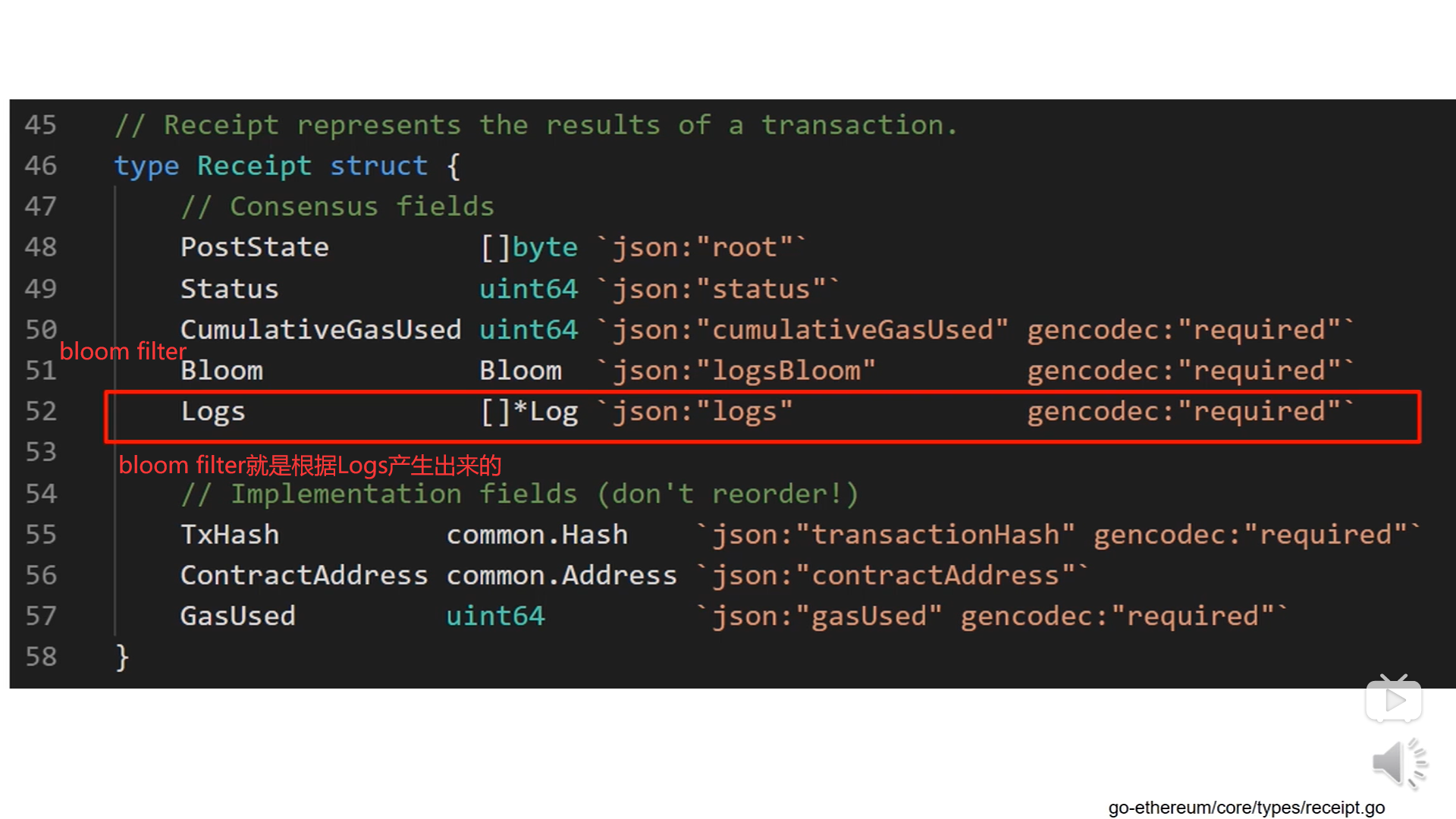
上图是Receipt的数据结构,每个交易执行完之后,形成一个收据,记录这个交易的执行结构,Bloom域就是Bloom filter,Logs为数组,每个收据可以包含多个Logs,这个收据的Bloom filter就是根据这些Logs产生出来的。
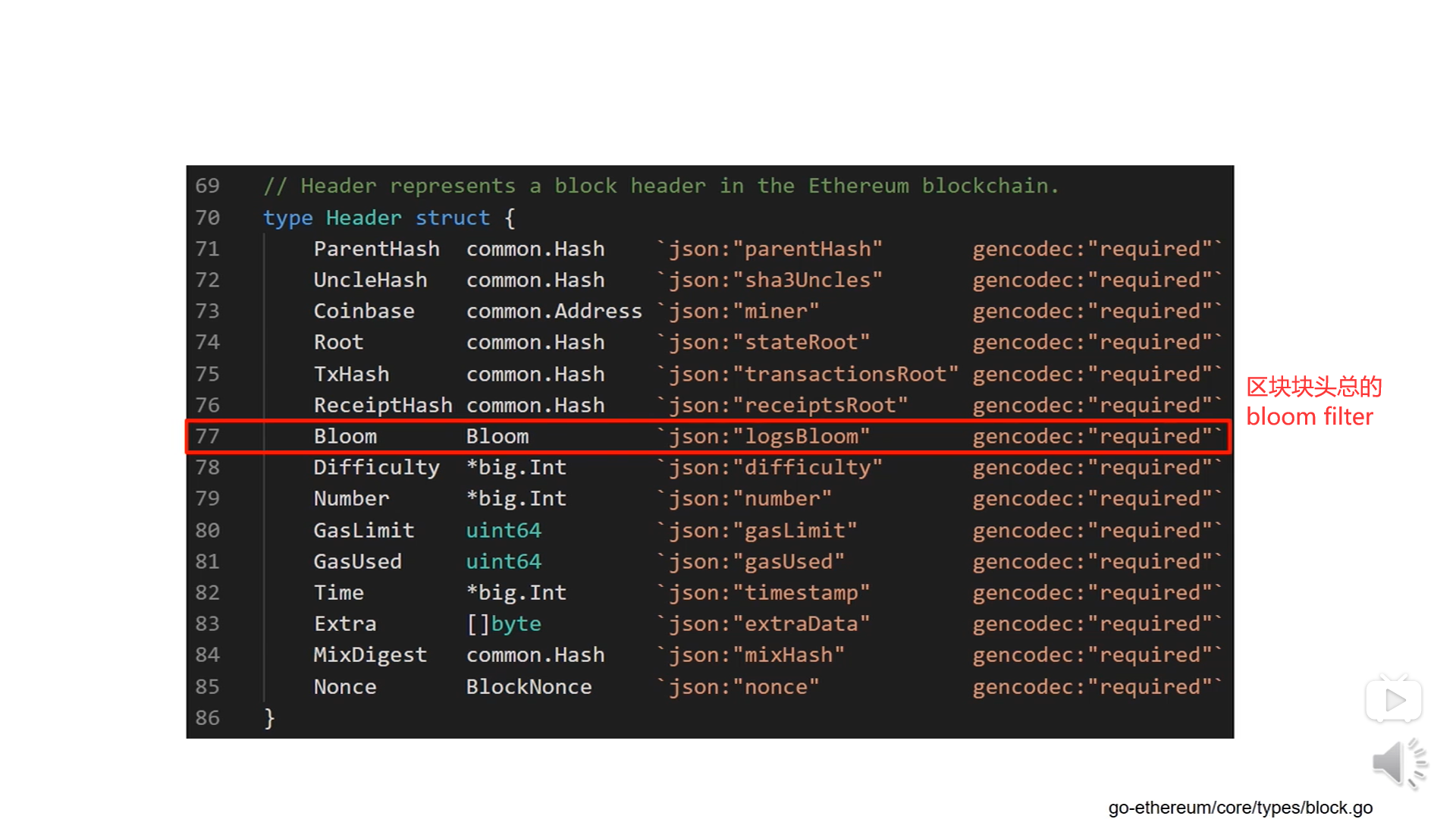
上图为区块的块头的数据结构,Bloom域是整个区块的Bloom filter,是由每个收据的bloom filter合并在一起得到的
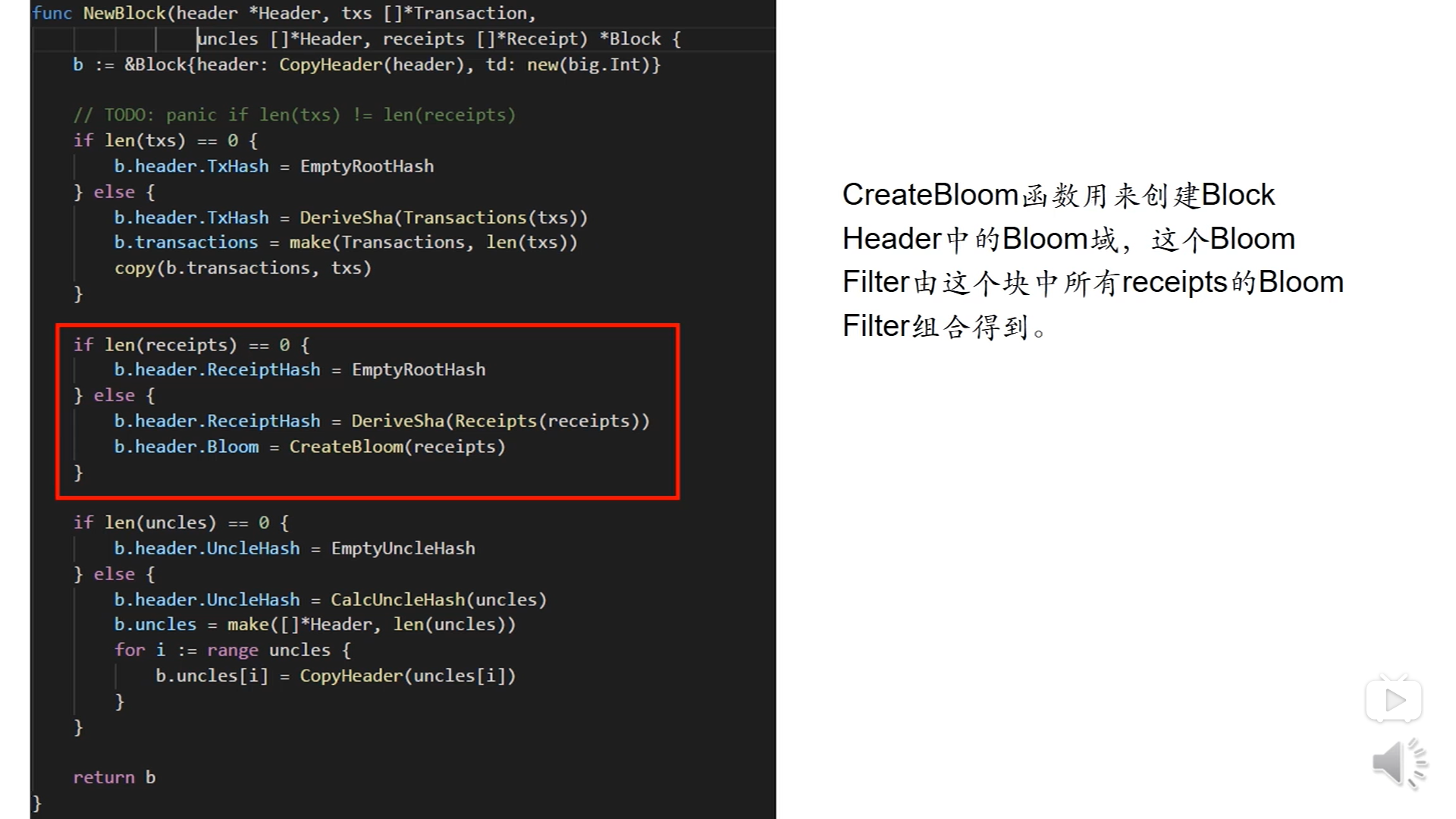
上图中的红框中的代码就是创建区块的块头中的Bloom filter,通过调用CreateBloom这个函数
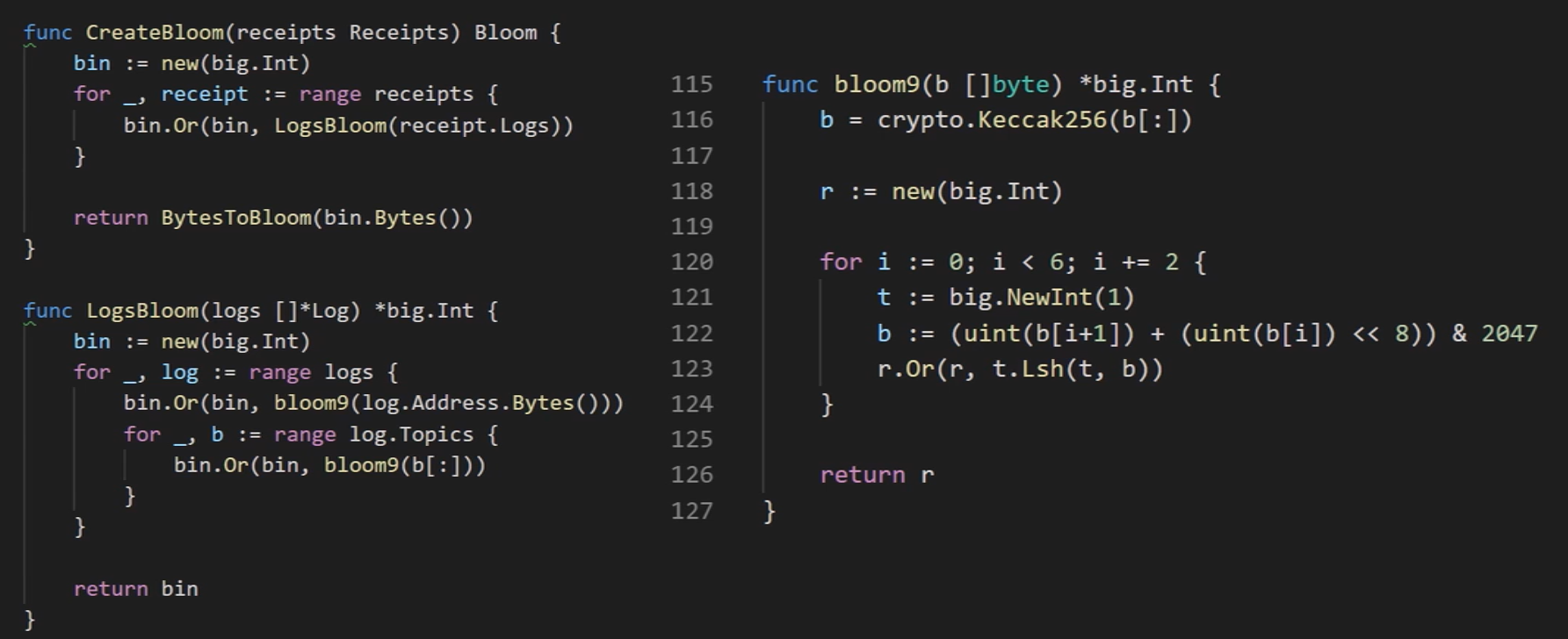
三个相关的代码实现,CreateBloom的三个参数是这个区块中的所有收据,这个for循环对每个收据再通过调用LogsBloom函数生成这个收据的bloom filter,然后把生成的bloom filter使用Or操作合并起来得到整个区块的bloom filter;
LogsBloom的功能是生成每个收据的bloom filter,他的参数是这个收据的Logs数组,每个收据里面包含一个Logs数组,这个函数有两层for循环,外层循环对每个一Log进行处理,首先把这个Log的地址取哈希之后加到Bloom filter里面,bloom9是bloom filter中使用的哈希函数,内层循环把这个Log中包含的每个topic加入到Bloom filter里,这样就得到了这个收据的bloom filter
bloom9是bloom filter中使用的哈希函数,和我们讲的有所区别,我们例子中的哈希函数是把集合中的每个元素映射到digest中的某一个位置,我们说这个集合要生成一个digest,哈希函数就是把每个函数映射到这个digest中的某一个位置,把这个位置置为1。这里所说的bloom9是把输入映射到digest中的三个位置(也就是说,把三个位置都置为1):b为32个字节的哈希值,r是最后返回的bloom filter,这里初始化为0,接下来循环,把刚才生成的32个字节的哈希值前六个字节,每两个字节组成一组,拼接在一起,然后&2047(相当于对2048取余),得到了一个位于0-2047区间里的数,之所以要这样做,是因为以太坊中bloom filter的长度是2048位,循环的最后一行把1左移 ,然后合并到上一轮得到的bloom filter里(通过Or运算),经过三轮循环,把三个位置置为1后,返回创建的bloom filter

查询某个bloom fiter里是否包含了感兴趣的topic呢?
通过调用BloomLookup函数来实现,查找bin这个bloom filter里有没有包含我们要找的topic,首先用bloom9函数将topic转换成一个byte vector,然后把他和bloom filter取And操作,看看得到的结果是不是和byte vector相等(这个bloom fiter中可能还包含别的topic,所以要先做一个And,然后再和他自身比较),相当于判断一下我们要找的topic在bloom fiter中对应的位置是不是都是1