对于基于工作量证明的区块链系统来说,挖矿是保障区块链安全的一个重要手段。
Block chain is secured by mining.比特币中的挖矿算法,总的来说是比较成功的。
bug bounty:有的公司悬赏来找软件中的漏洞,如果能找到软件中的漏洞,就可以得到一笔赏金。
比特币的挖矿算法,是一个天然的bug bounty,如果你能找到里面的漏洞,或者是某一个挖矿的捷径,就能有很大的利益。所以比特币的挖矿算法,是比较成功的,能够经受时间的检验的
但是比特币的挖矿算法也有一些值得改进的地方,其中有一个饱受争议的问题,就是挖矿设备的专业化(用普通的计算机挖不到矿),很多人认为,这和比特币去中心化的思想时背道而驰的,也和比特币的设计初衷是相违背的(one cpu one vote,理想情况下,让普通老百姓也能参与挖矿的过程),这样有恶意的攻击者想要聚集50%的算力发动攻击,这个难度就会大得多,所以这之后的很多加密货币,包括以太坊在内,都是要做到ASIC resistance。
如何设计一个对ASIC芯片不友好的mining puzzle?
常用的做法是增加这个puzzle对内存访问的需求,也就是所谓的memory hard mining puzzle,ASIC对普通cpu的主要优势是算力强,但是在内存访问的性能上,并没有那么大的优势,所以如果我们能设计一个对内存要求很高的puzzle,那么就能够起到遏制ASIC芯片的作用。
这里面的一个早期的例子就是LiteCoin(莱特币),曾经市值仅次于比特币的第二大加密货币,它用的puzzle是基于scrypt(对内存要求很高的哈希函数,以前用于计算机安全领域,和密码相关的),具体思想:开设一个很大的数组,然后按照顺序填充一些伪随机数
注:这里的seed的去哈希,实际上是通过一些运算得到一个数
这里我们不能真的用随机数,用随机数我们没有办法验证,这个数组的取值是有前后依赖关系的,需要求解puzzle的时候,按照伪随机的顺序,从这个数组中读取一些数,每次读取的位置,也是和前一个数是相关的(每次读取的数,通过一些运算(哈希运算),得到下一个需要读取数的位置,以此类推),如果这个数组足够的大的话,那么对于矿工来说,就是memory hard,因为如果不保存这个数组,挖矿的复杂度会大幅度上升(需要读取数组中的数的时候,没有保存这个数组,还得从第一个算,算出第一个位置的值,然后要读取第二个位置的数,还要继续计算到第二个位置的值,计算复杂度会大幅度地上升,所以要想高效的挖矿,这个内存区域是需要保存的),有的矿工可能保存一部分内存区域的内容(比如只保存奇数位置的元素,当用到偶数位置,根据另一半算一下),有时候也叫做time-memory trade off。
好的地方:对矿工来说:memory hard
不好的地方:对轻结点来说,也是memory hard,求解puzzle很难,但是验证应该是很简单的,这个问题就在于,验证这个puzzle需要的内存区域跟求解这个puzzle的内存区域几乎是一样大的,对于早期的计算机安全领域,没有这个问题(因为他没有轻结点),所以,这就导致,这个内存区域不能设置得太大,比如你设置的1G大小的内存区域,问题不大,但是是手机上的app,就太大了,所以实际使用莱特币的时候只有128k。

当初,莱特币发明的目标,不止是ASIC resistance,还有GPU resistance(挖矿连GPU都不要用),大家都用普通的cpu挖矿,后来就出现了GPU挖矿,现在出现了ASIC芯片挖矿,实验证明,莱特币要求的128k内存不足以对ASIC芯片的生产和设计带来实质性的障碍,所以从这点来说,莱特币设计的目标是没有达到的,但是对于解决莱特币的能启动问题,是很有帮助的,任何一个加密货币都存在能启动的问题,包括比特币(一开始的时候没有人知道你这个货币,没有人理你,没有人参与),而且对于基于工作量证明的加密货币来说,挖矿人太少是不安全的,因为发动恶意攻击的难度就太低了,比特币的早期也是不安全的。解决能启动的问题实际上是一个循环迭代的过程,一个好的加密货币是可以经过时间的检验的。
除了mining puzzle这个区别之外,莱特币和比特币的区别还有就是出快速度是比特币的四倍,出块间隔是两分半,除此之外,这两种加密货币基本上是一样的。
以太坊也是一种memory hard mining puzzle,但是在设计上和莱特币有很大的不同,以太坊用的是两个数据集,一大一小,小的是一个16M的cache,大的是一个1G的dataset(DAG),这1G的数据集是从这16M的cache生成出来的,为什么要这样设计?一大一小?
就是为了便于验证,轻结点只需要保存16M的cache就可以了,只有需要挖矿的矿工才需要保存1G的数据集,基本思想是:这个小的数据集cache的生成方式跟前面所讲的数组的生成方式是比较类似的,首先从一个种子节点,通过一些运算,算出数组的第一个元素,然后依次取哈希,第一个元素取哈希得到第二个元素,以此类推,将数组从前往后填充伪随机数,得到这个cache,之后就和莱特币就不一样了,
莱特币:直接从数组当中按照伪随机的顺序读取一些数,然后进行运算。
以太坊:先生成一个更大的数组,这个大数组比cache大得多,小的cache和大的dataset都是定期增长的,每隔一段时间,会增大,因为计算机的容量也是定期增长的,比如现在,这个大的dataset已经增长到2.5G了,大的数据集的生成方式:每个元素都是从小的cache里按照伪随机的顺序读取一些元素,方法和刚才讲的莱特币里面求解puzzle的过程是类似的:第一次比如说读取A位置的元素,读取完之后,对当前的哈希值进行一些更新迭代,算出下一个要读取的位置,比如说B位置,然后再算出下一个要读取的位置,从cache中依次读,一共读256次,最后算出来一个数,最后放在dataset的第一个元素,然后第二个元素也是一样的。
求解这个puzzle的时候,用的是这个大数据集中的数,cache是不用的,按照为随机的顺序 ,从这个大的数据集中读取128个数。一开始的时候,根据这个区块的块头,包括里面的nonce,算出一个初始的哈希,根据这个哈希,映射到大数据集中的某个位置,把这个位置上的数读取出来,然后进行一些运算,得到下一个要读取的位置……(这里有个区别,除了把算出的位置要读,还要读取它的下一个位置的元素也要读出来,所以每次读的时候,回一次读取两个位置的元素,这样循环64次,每次读两个,一共128个),最后算出一个哈希值来,跟挖矿难度的目标阈值比较一下,是不是符合难度要求,如果不是的话,把block header的nonce替换一下,然后重新算
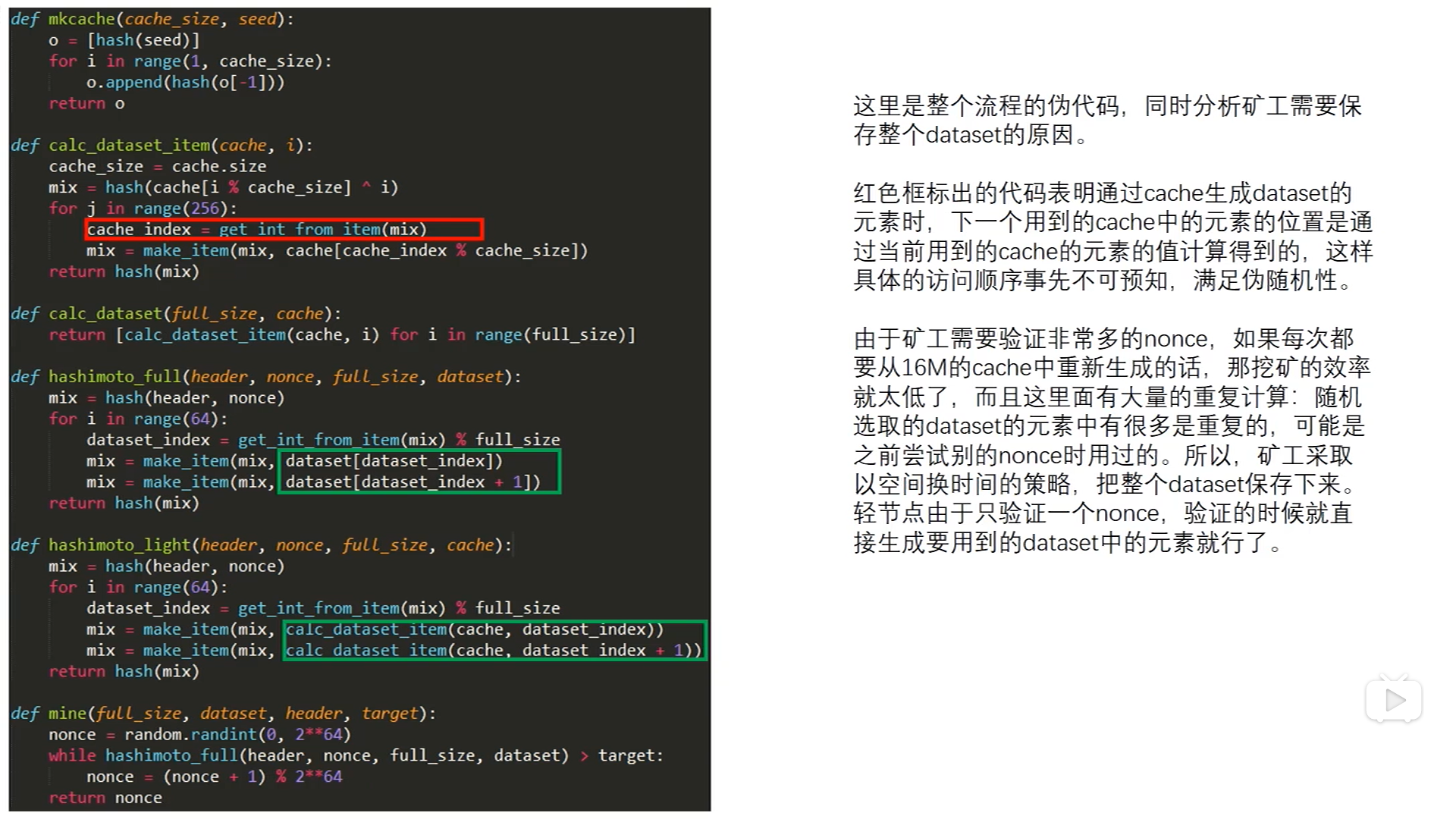
ethash算法伪代码:




上图中的两个函数:
第一个函数,矿工用来挖矿的函数,以太坊,和比特币一样,挖矿只用到块头的信息(这样的话,轻结点只下载块头,就可以验证这个区块,是否验证这个区块是否符合挖矿的难度要求),第二个参数nonce,表示当前尝试的nonce值,第三个参数full_size是大数据集中元素的个数,每三万个区块会增加一次,增加原始大小的1/8,也就是1G的1/8,等于8M,最后的参数dataset,就是前面生成的大数据集。
挖矿:首先根据块头的信息,和当前的nonce算出一个初始的哈希,然后经过64轮循环,每个循环读取大数据集中相邻的两个数,读取的位置,是由当前哈希值计算出来的,然后根据当前位置上的数值,更新当前的哈希值(每次读取的相邻位置上的值是没有联系的,虽然在位置上相邻,但是生成的过程是独立的,每个都是由前面那个16M的cache中的256个数生成的,而且这256个数的位置,是按照伪随机的顺序产生的),这和生成大数据集的元素的方法是类似的,最后返回一个哈希值,和挖矿难度的目标阈值相比较。
下面这个函数,是轻结点用来验证的函数。也是有四个参数,但是含义和矿工用的函数有所不同,轻结点是不挖矿的,当他收到某个矿工发布的区块的时候,这里用来验证的这个函数的第一个参数header,是这个区块的块头,第二个nonce是发布的这个区块的nonce(是矿工选好的),轻结点的任务是验证这个nonce是否符合要求,验证用的是16M的cache,也就是最后这个参数,注意,第三个参数full_size仍然是大数据集中的元素个数
验证:也是64轮循环,看上去和挖矿的过程类似,只有一个地方有区别,每次需要从大数据集读取元素的时候,因为轻结点没有保留大数据集,所以要从cache重新生成。

那以太坊设计的这个puzzle,实际效果怎么样?
到目前为止,以太坊挖矿,主要还是以GPU为主,用ASIC矿机的很少,所以从这点上来说,他比莱特币要成功,起到了ASIC resistance的作用,这个和以太坊挖矿算法需要的大内存是很有关系的
ethash:eth+hash,矿工挖矿需要1g的内存,跟莱特币的128kb,差了有8000多倍,即使16M的cache和128kb相比,爷要大了100多倍,而且还是按照这两个数据集最初的大小来算的。
以太坊没有出现ASIC矿机,还有另外一个原因:
以太坊从很早开始就计划,要从工作量证明转向权益证明(PoW->PoS[proof of stake]),就是按照所占的权益进行投票形成共识(类似股份制公司按照股份多少来投票,这样就不挖矿了),这样对于ASIC矿机的厂商来说,是一个威胁,因为ASIC矿机的生产周期是很长的,一款芯片,从设计研发到最后的生产,一年的周期就已经算是很快的了,而且研发的成本也很高,那么转向权益证明之后就不挖矿了,那么投入的研发费用都白费了。
其实,以太坊到现在为止,还是基于工作量证明,转移的时间点一再往后推迟,要想达到ASIC resistance,一个简单的办法,就是不断地“吓唬大家”,以太坊成为主流的加密货币,其实也就是最近的两年的时间
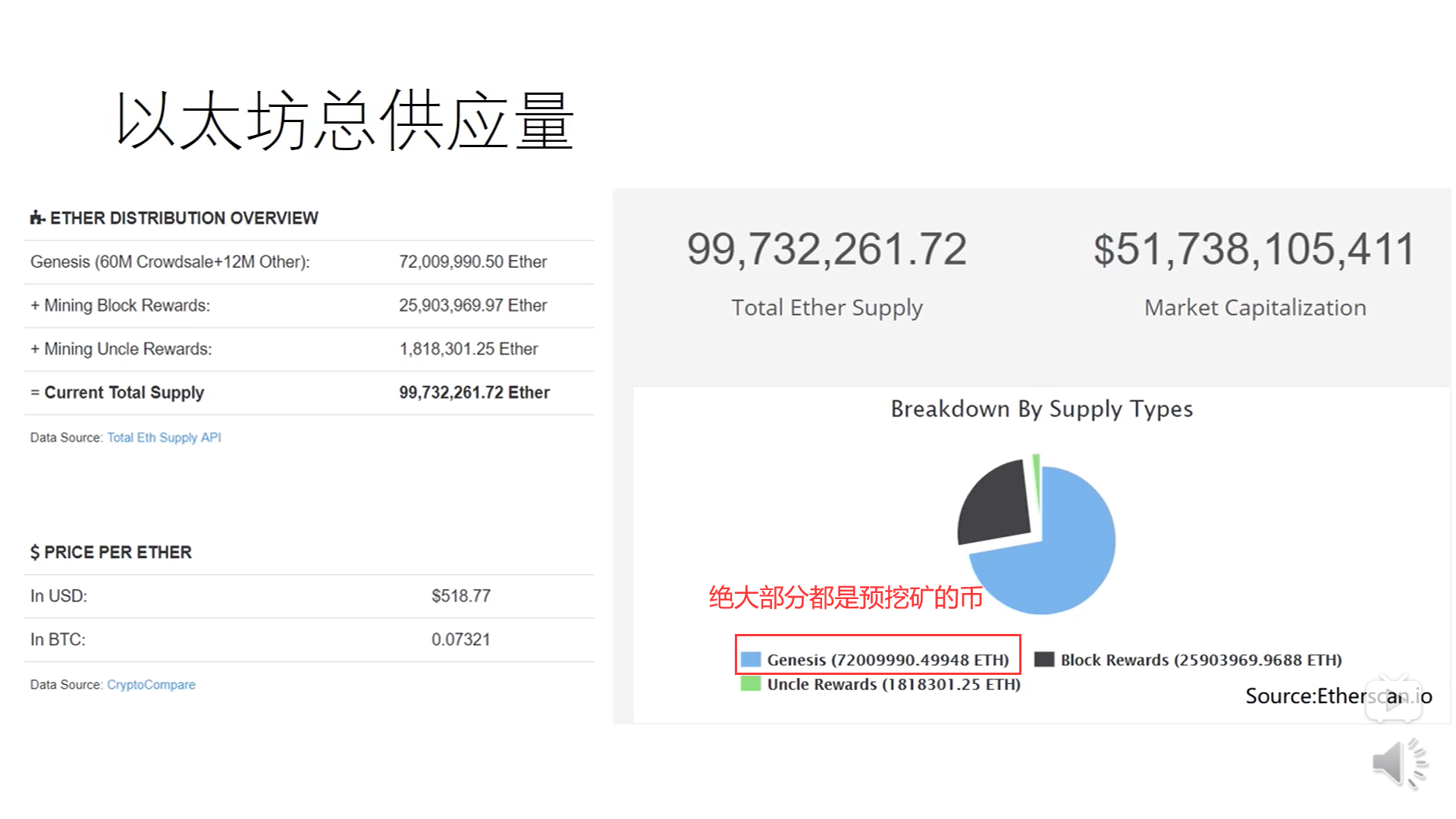
关于挖矿:以太坊采用了预挖矿的过程(pre-mining)。
所谓的预挖矿,并不是说真的去挖矿,而是说在当初发行货币的时候,预留一部分货币,给以太坊的开发者,将来这个加密货币成功了的话,这些预留的币就变得很值钱了,像以太坊的早期开发者,现在都很有钱,和比特币相比,比特币就没有采用pre-mining的模式,所有的比特币都是挖出来的,只不过早些时候,挖矿的难度要容易得多,与pre-mining相关的概念叫做pre-sale(把pre-mining预留的那些币,通过出售的方式来换取一些资产,然后用于加密货币的开发工作,有点像拉风头,或者众筹)。
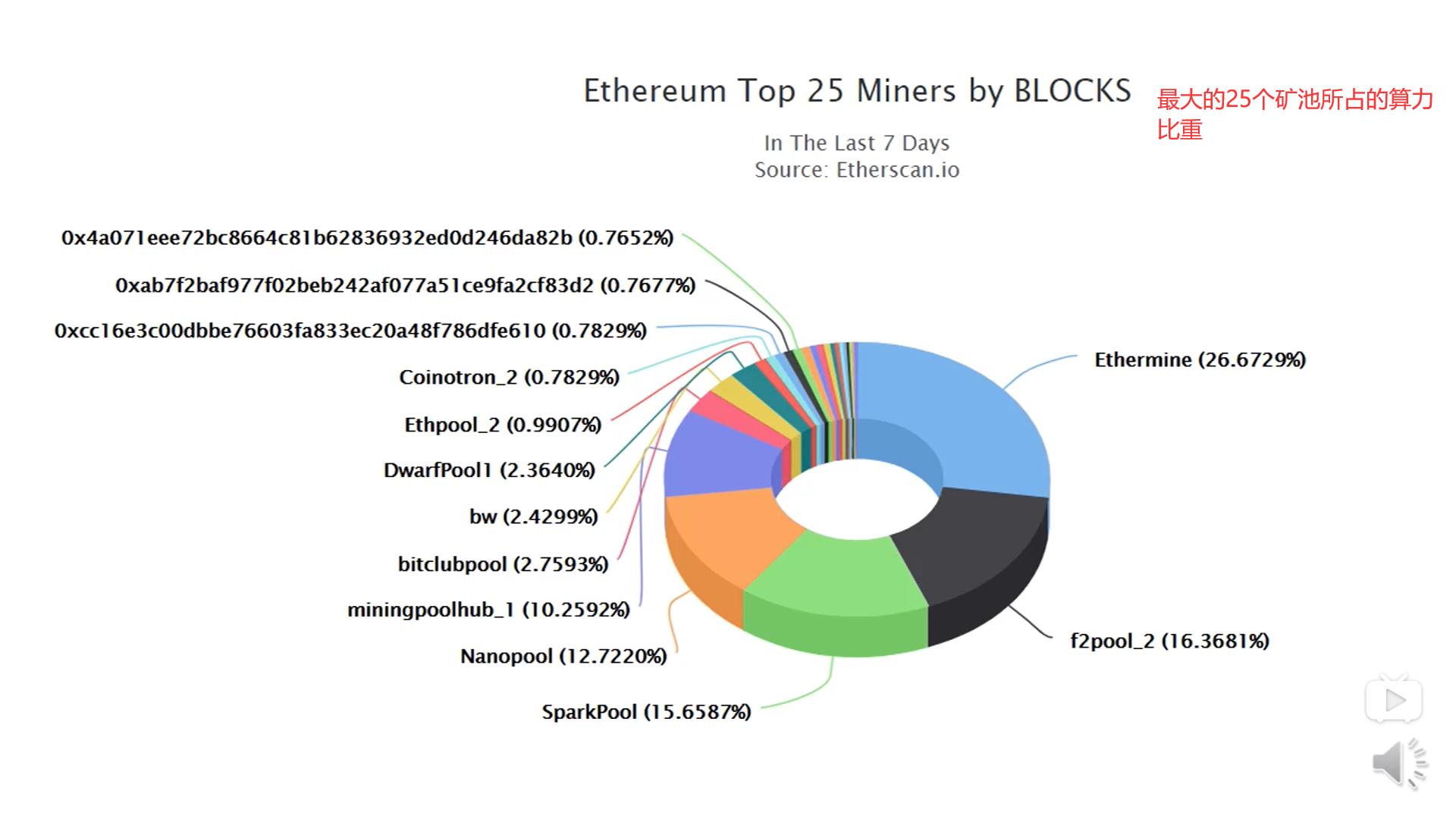
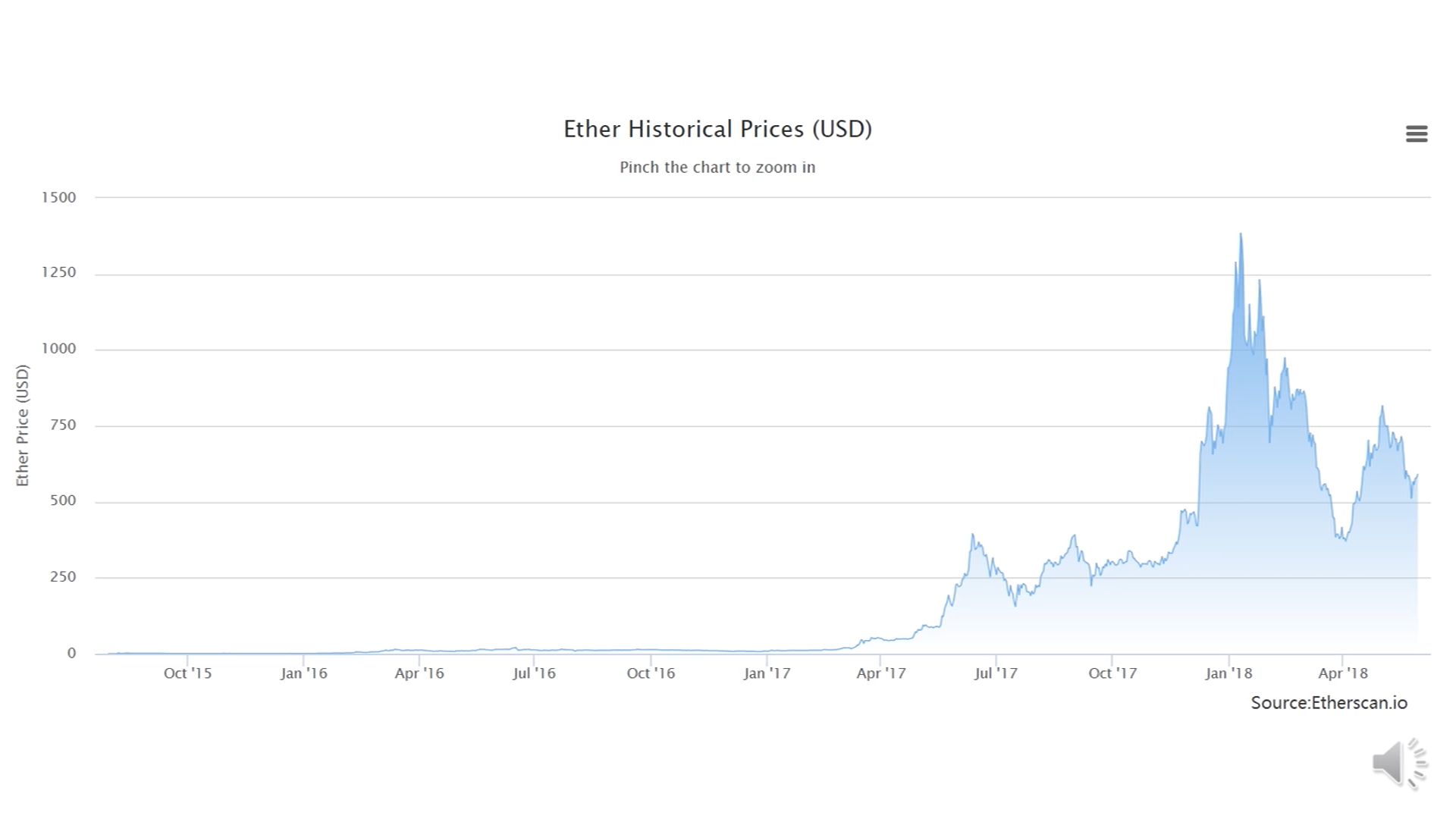
以太坊的一些统计数据:
以太坊价格变化(2017年-2018):
以太坊市值:
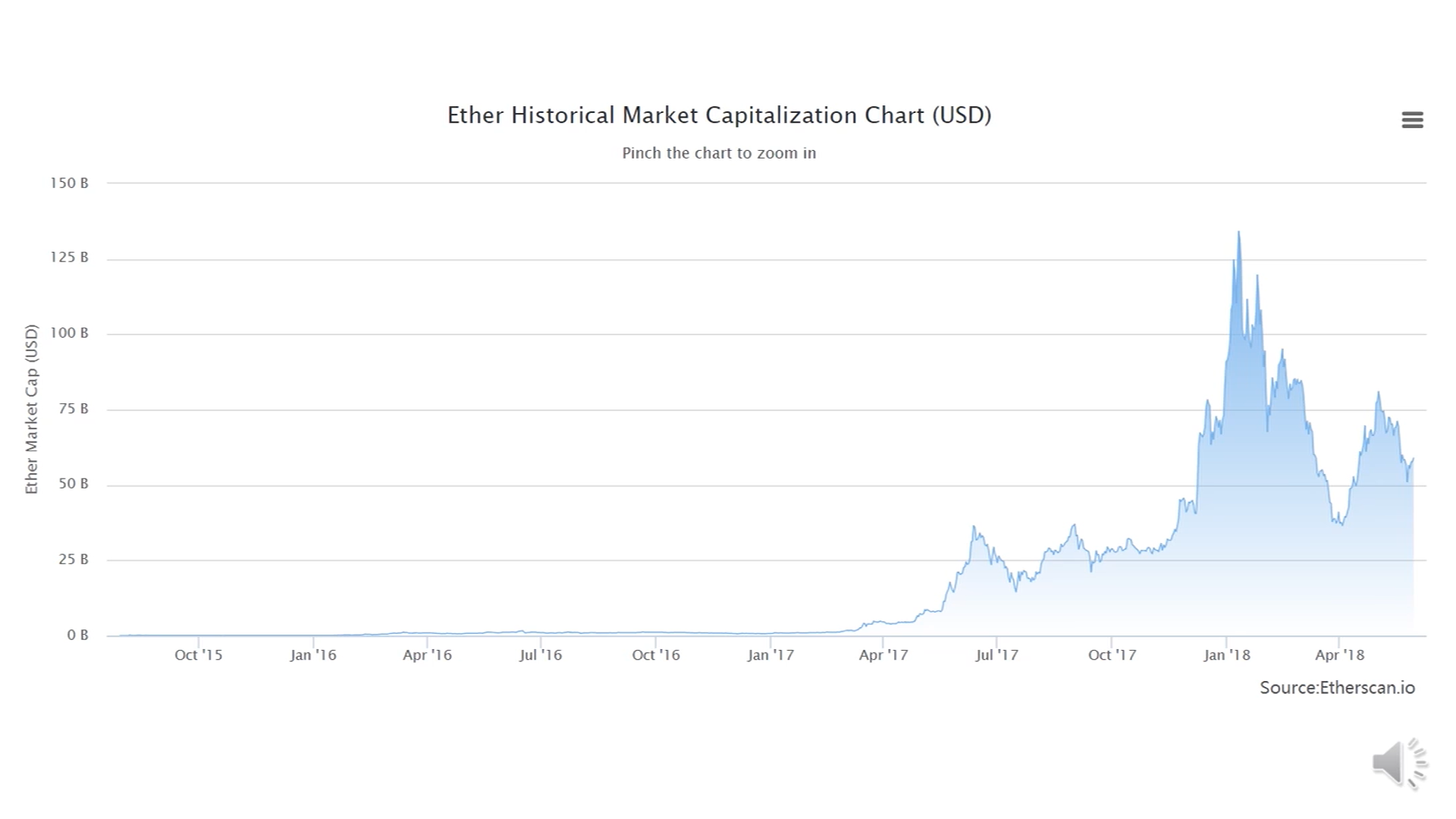
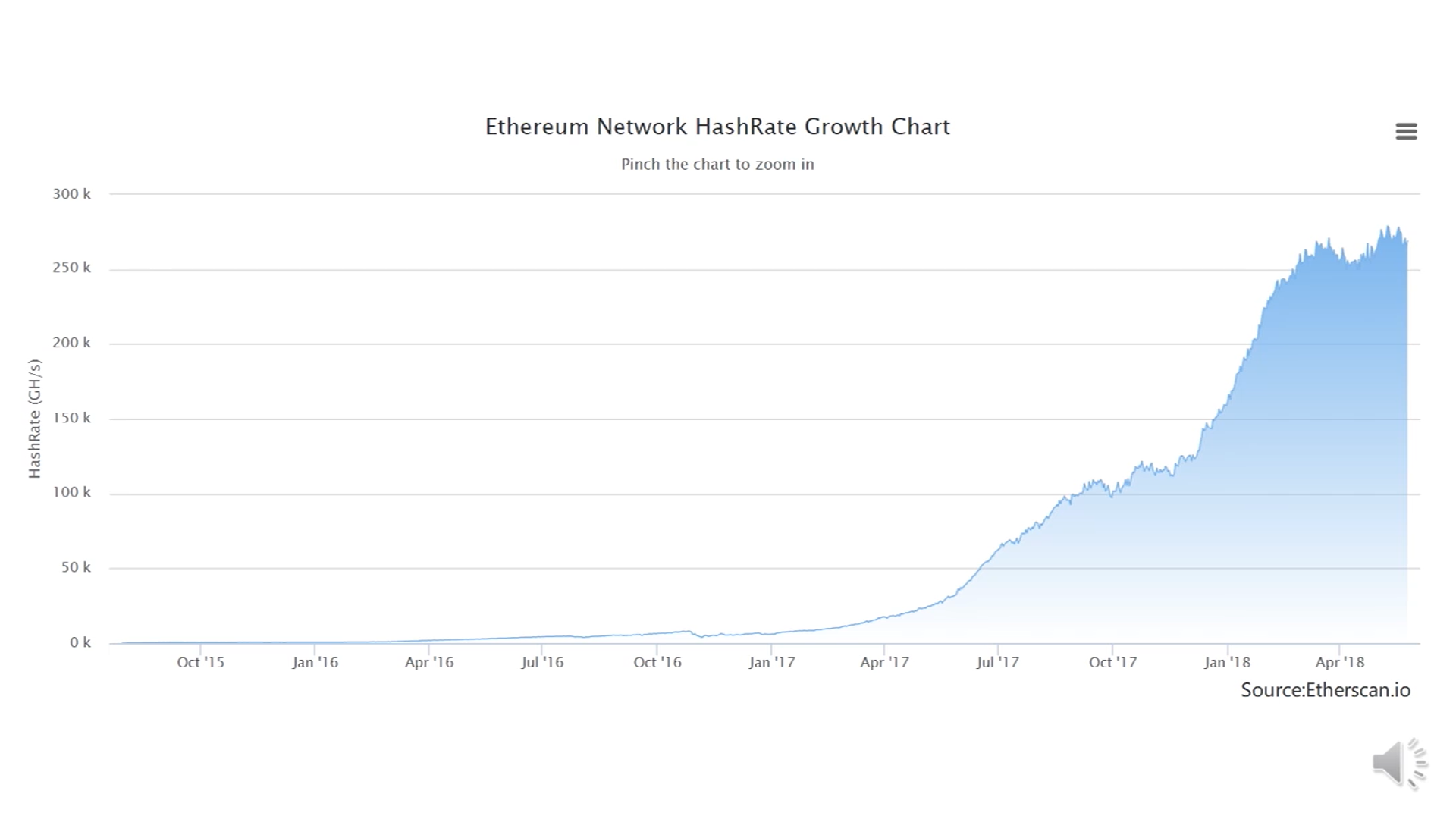
上图中的HashRate指的是所有的矿工加在一起每秒钟计算的哈希次数
不同的加密货币,如果采用的mining puzzle不同的话,那么他们的HashRate是不可比的。
如果让通用计算机参与挖矿,发动攻击的成本也会大幅度得降低,如果一个大公司有几百万台甚至几千万台服务器,如果这个公司有恶意,就可以临时征用服务器,来挖矿,没有必要专门买特有的设备。所以有些人认为,让通用计算机参与挖矿是不好的。